

Nowadays, “machine learning”, “deep learning” or “artificial intelligence” (aka “AI”) are becoming more and more popular. These concepts immediately bring to mind very complex algorithms which, based on a large amount of past data, would be capable of detecting events or taking decisions based on current data or even predicting future events or data.
Of course, this implies high calculation speed and large data storage. This is why it was initially reserved for the most powerful servers. But since couple of years, it seems like it would be possible to apply the same technologies inside ultra-limited-resources objects that we can find in the IoT world.
Today we offer to look into this topic through a series of articles. We will first look more precisely into the resource constraints of IoT objects. Then we will explain what “machine learning” really means. And finally we will see if it is really possible to combine both and what kind of benefits we can get from it.
We followed the exact same approach at Next4 when conceiving our “N402” tracker, so it will be used as an example of an “IoT device” throughout this series.
1. – Small connected/autonomous objects and their constraints
1.1 Computation speed and storage capacity
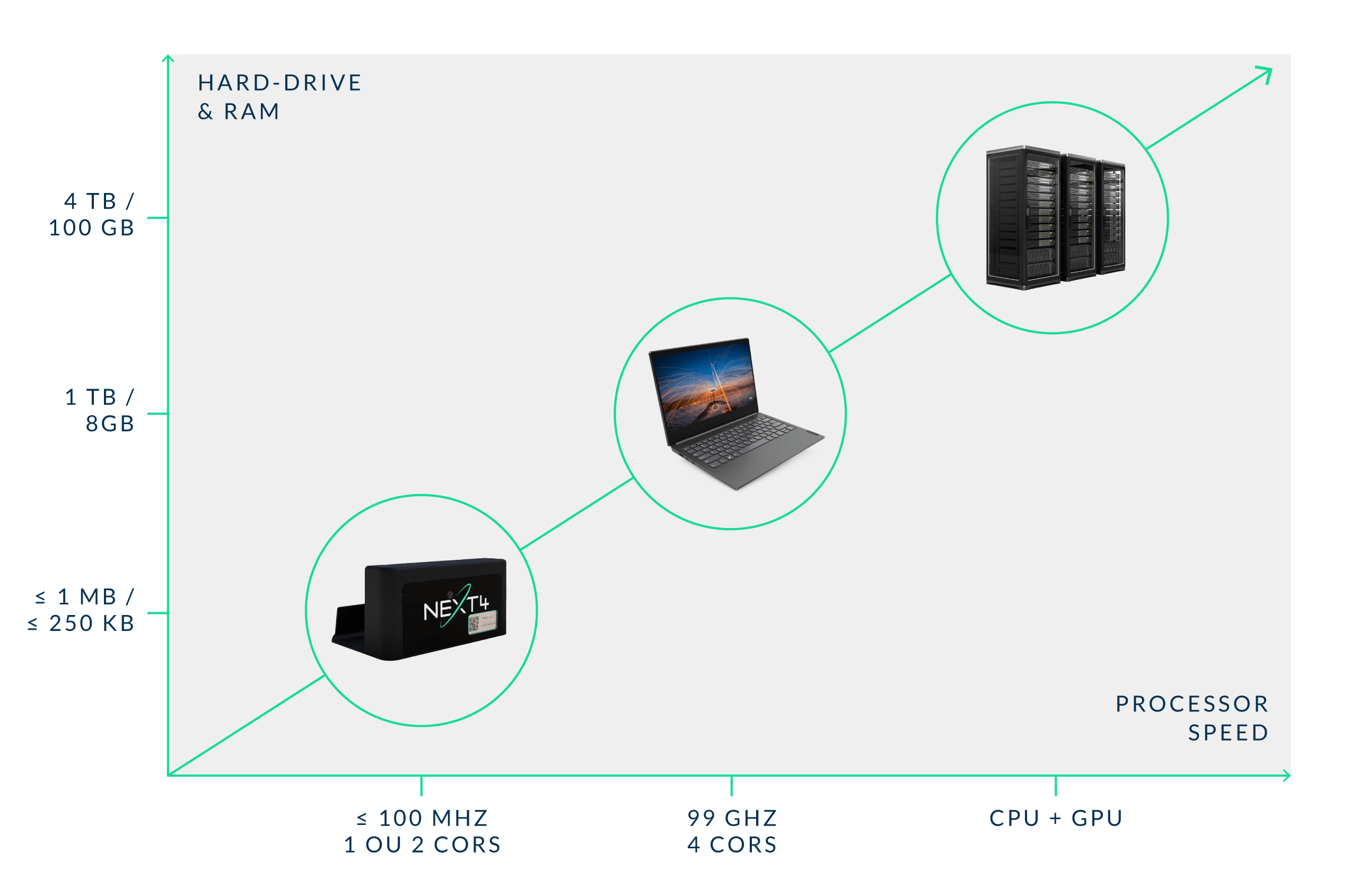
If we had to sort the various electronic and computing devices based on their computation speed and storage capacity, our average personal computer would be in the middle, typically embedding a 4-core processor running at 3GHz, a 1TB hard-drive and 8GB of volatile memory (aka RAM).
At the top we would find the servers : way too expensive for individuals and even for most companies, they are rented by OVH, Amazon or Google for instance. They bring, along with their main processor (the CPU), a dedicated coprocessor (called GPU) optimized for complex computing with up to 100 GB of RAM.
Here, we do not even speak of the “supercomputers” that most of us will never use, even in a professional environment.
Our small IoT objects would stand at the bottom. These products can be various, with very different functionalities and thus very different computing speeds and/or storage capacities. But if we take the example of Next4’s N402 tracker, its characteristics are the following :
- 2-core microprocessor running at 64 MHz
- 512KB Flash (hard-drive)
- 256KB of RAM
Why such constraints? Why can’t a small IoT product embed the same hardware as our personal computers?
- for the size: even if electronic components get smaller and smaller as time goes by, computer processors, hard drives and RAM modules take up too much space and can not fit in a small product.
- for the cost: the price of a personal computer is usually above 500$, while the target cost for most IoT products is below 100$.
- for the battery life: unlike your smartphone that you will re-charge every night, in most cases, IoT products must guarantee over a year of battery life. In order to save as much power as possible, their processor must run a lot slower.



Based on the difference between a standard computer and our N402 tracker (roughly a ratio of 200 on computing power and a ratio of 30,000 or more on storage), we can easily understand that we will not be able to embed the same algorithms on both platforms.
1.2 Embedded software in IoT products : a strong need for predictability and reliability.
When discussing “machine learning” algorithms embedding with a software developer, his first and major concern will relate to the predictability and reliability of his IoT product.
Indeed, when a web service or website crashes, it only takes few minutes, or in worst cases few hours, to make it up and running again. On the other hand, if our shipping container tracker crashes while it is installed on a container currently sailing in the middle of the ocean, it will takes weeks or even months before we can get hold of it and put it back in service… and during that time, service will not be provided to our customer.
Note that this is not only true for “small IoT products” : your car’s embedded software must also be 100% reliable!
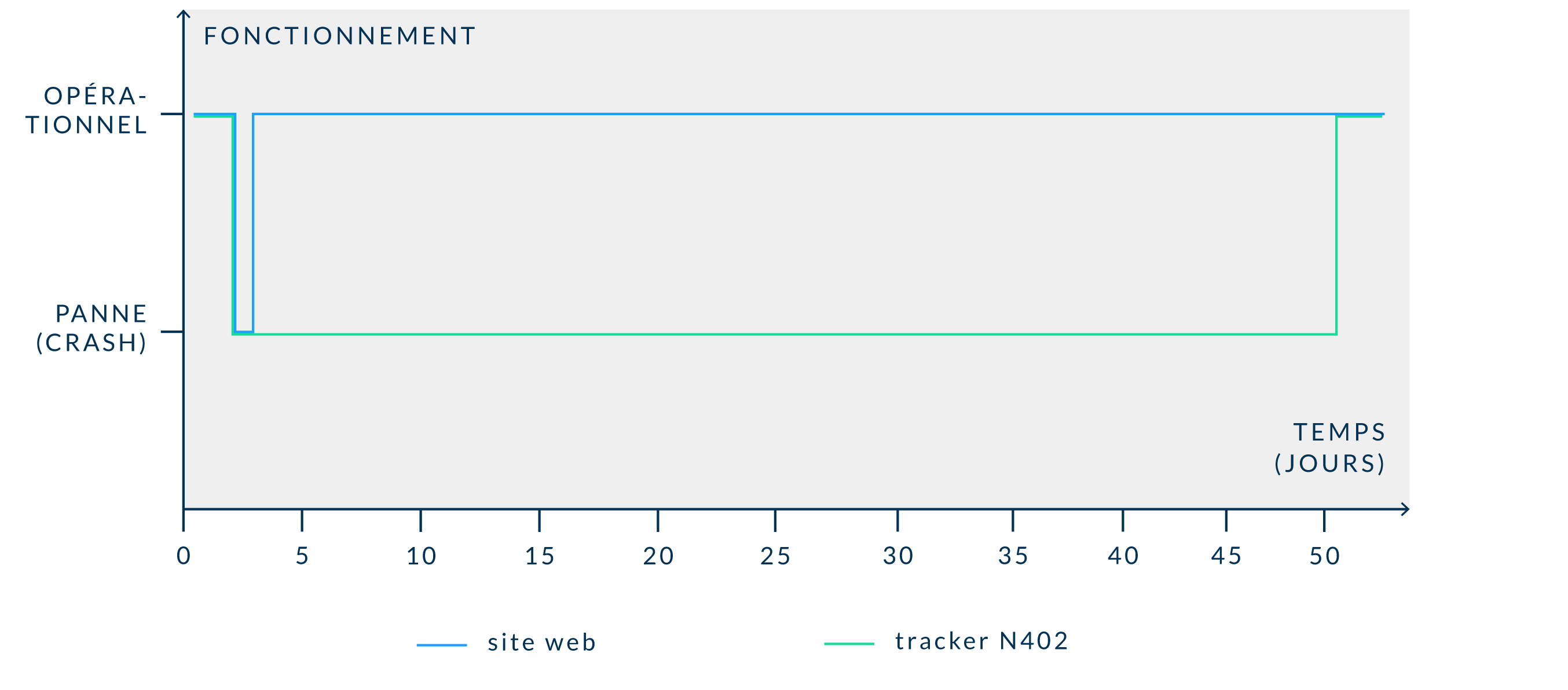
In order to guarantee this reliability, aside from all the test campaigns that have to be (and will be) run, it is mandatory to fully understand and master the embedded software. That also means knowing exactly how it will behave under any possible circumstance. That is what predictability is all about.
That need comes in conflict with some ideas about machine learning or artificial intelligence, like “let’s allow the device take its own decision” or “let’s implement in that object a super-complex algorithm found by a computer and that no human being would be able to understand”.
How can we predict and guarantee the product’s behavior if we do not understand its logic or, even worse, if its logic is not decided in advance?
2 – Intelligence in embedded software: Pros and cons
2.1 The smart server / dumb device guideline
As we just saw, developers might be reluctant to implement software they do not fully understand into an IoT object.
But, a long time before machine learning or AI emerged, most developments followed this guideline: “Intelligence must reside as much as possible on the server-side rather than on the device-side”.
Reason is straightforward: the dumber the object is, the simpler its software will be. And the simpler the software is, the more reliable and robust it will be.
On the contrary, if you want to make your device smarter, you will have to add more lines of code and you will potentially insert bugs in it. And, as stated above, it is a lot easier to fix a bug on server-side than on device-side.
So, for instance, if a large amount of data has to be analysed, it is better to send it to a server to compute it rather than doing it on the device itself.
2.2 The emergence of the Edge Computing area
Coming in conflict with this long-time established guideline, the Edge Computing concept suggests using as much as possible the embedded resources of each device to improve the functionalities they can provide.
Among other benefits, it allows to:
- improve system responsiveness: if data is analyzed by the device itself rather than sent to a server, system response won’t be affected by the transmission delay.
- reduce the amount of data exchanged between the device and the server.
- reduce the power consumption required for those transmissions.
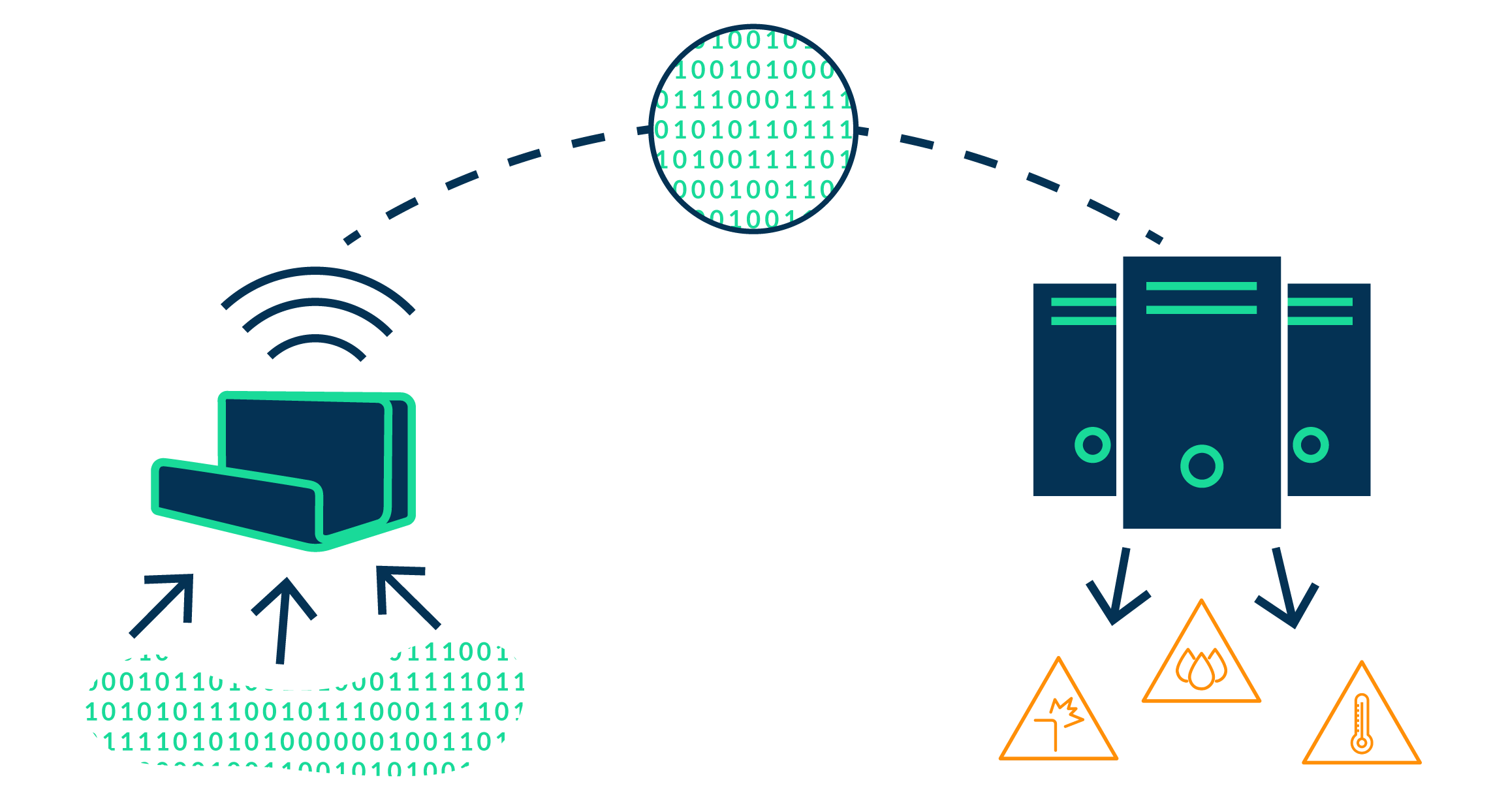
Coming back to our N402 example, the detection of the different events during a shipment (shocks, door opening, crane on boat, temperature or humidity excess, etc…) are based on data coming from various sensors (g-sensor, gyroscope, pressure, temperature, humidity sensors, etc…). We took the approach of computing the data in the tracker itself, so communication with our servers only occurs when events really take place . This was the only way to significantly reduce the frequency and amount of exchanged data (without any information loss) and insure multiple-years of battery life.
To sum up, our small IoT devices will never have the same computing speed or storage capacity than our personal computers, and common sense would encourage to limit the intelligence embedded in those objects.
However, if the embedded software reliability and predictability can be guaranteed, adding some complex algorithms into it would allow the optimization of the overall system, and may even produce breakthrough functionalities to end-customers.
In this context, is it possible to consider implementing machine learning algorithms in such small objects? This is what we will see in an upcoming article…
by Julien Brongniart